
Our Happy Clients


























There are different definitions of microservices, and searching the Internet provides many good resources that provide their own viewpoints and definitions. However, most of the following characteristics of microservices are widely agreed upon:
- They encapsulate a customer or business scenario. What is the problem you are solving?
- They are developed by a small engineering team.
- They can be written in any programming language and use any framework.
- They consist of code and (optionally) state that are independently versioned, deployed, and scaled.
- They interact with other microservices over well-defined interfaces and protocols.
- They have unique names (URLs) that can be used to resolve their location.
- They remain consistent and available in the presence of failures.
You can summarize this into:
Microservice applications are composed of small, independently versioned, and scalable customer-focused services that communicate with each other over standard protocols with well-defined interfaces.
We covered the first two points above in the preceding section, and we will now expand on and clarify the others.
Can be written in any programming language and use any framework
As developers, we should be free to choose whatever language or framework we want, depending on our skills or the needs of the service. In some services, you might value the performance benefits of C++ above all else, while in others, the ease of managed development in C# or Java might be most important. In some cases, you may need to use a specific third-party library, data storage technology, or means of exposing the service to clients.
Once you have chosen a technology, this brings us to the operational or lifecycle management and scaling of the service.
Start your solution today
State storage between application styles
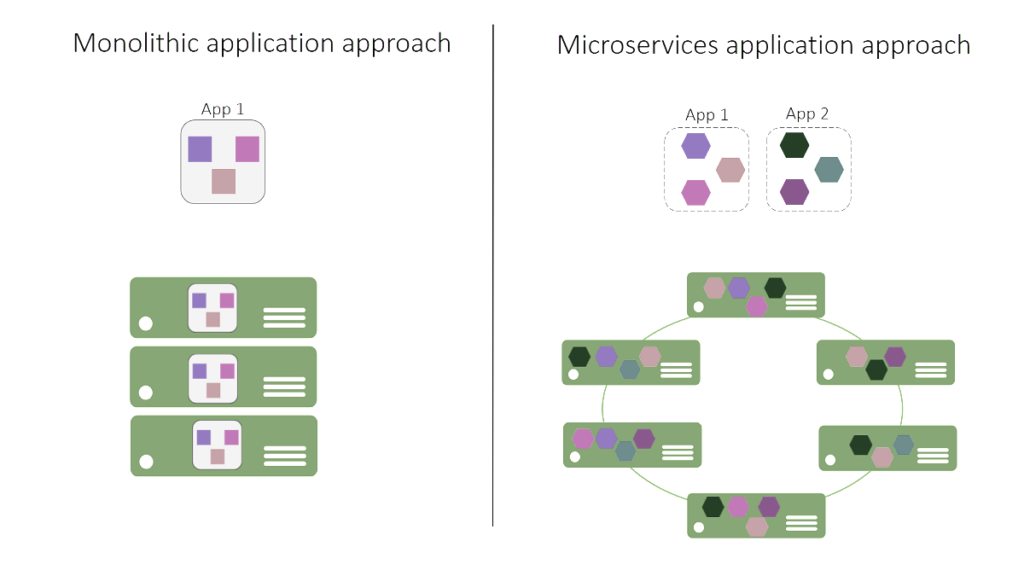
On the left is the monolithic approach, with a single database and tiers of specific technologies.
On the right is the microservices approach, a graph of interconnected microservices where state is typically scoped to the microservice and a variety of technologies are used.
In a monolithic approach, typically there is a single database used by the application. The advantage is that it is a single location, making it easy to deploy. Each component can have a single table to store its state. The hard part is that teams need to be strict in separating state, and inevitably there are temptations to simply add a new column to an existing customer table, do a join between tables, and generally create dependencies at the storage layer. Once this happens, you can’t scale individual components. In the microservices approach, each service manages and stores its own state, meaning that it is responsible for in scaling both code and state together to meet the demands of the service. The downside to this comes in when there is a need create any views, or queries, of your applications’ data, since you will need to query across these disparate state stores. Typically, this is solved by having a separate microservice that builds a view across a collection of microservices. If you need to perform multiple ad-hoc queries on the data, each microservice should consider writing its data into a data warehousing service for offline analytics.
Versioning is specific to the deployed version of a microservice. It is required so that multiple different versions can be rolled out and run side by side. Versioning addresses the scenarios where a newer version of a microservice fails during upgrade and needs to be rolled back to an earlier version. The other scenario for versioning is performing A/B-style testing, where different users experience different versions of the service. For example, it is common to upgrade a microservice for a specific set of customers to test new functionality before rolling it out more widely. After lifecycle management of microservices, this now brings us to communication between them.
Interacts with other microservices over well-defined interfaces and protocols
Little has to be covered on this topic, other than to read the extensive literature on service-oriented architecture published in the past 10 years, since much of this was geared toward communication patterns. Generally, this now comes down to using a REST approach with HTTP and TCP protocols, and XML or JSON as the serialization format. From an interface perspective, it is about embracing the web design approach. But there is nothing stopping you from using binary protocols or your own data formats. Just be prepared for people to have a harder time using your microservices if these are openly available.
Has a unique name (URL) that can be used to resolve its location
Remember how we keep saying that the microservice approach is like the web? Like the web, your microservice needs to be addressable wherever it is running. If you are thinking about machines and which one is running a particular microservice, things will go bad quickly. In the same way that DNS resolves a particular URL to a particular machine, your microservice needs to have a unique name to discover where it currently is. Microservices need addressable names that make them independent from the infrastructure that they are running on. Of course, this implies that there is an interaction between how your service is deployed and how it is discovered, since there needs to be a service registry. Equally, there needs to be an interaction between when a machine failure occurs and what happens to your microservice, so that the registry service can tell you where it is now running. This brings us to the next topic: resilience and consistency.
Service Fabric as a microservices platform
Azure Service Fabric was born out of Microsoft’s transition from delivering box products, which were typically monolithic in style, to delivering services. Service Fabric was primarily driven by the experience of building and operating large services, such as Azure SQL databases, DocumentDB, and other core Azure services. We approached the business needs entirely for scale, agility, and independent teams, and we let the platform evolve over time as more and more services adopted it. Importantly, Service Fabric had to run anywhere, not just in Azure, but also in standalone Windows Server deployments.
The aim of Service Fabric is to solve the hard problems of building and running a service, such as failures and upgrades, and utilizing infrastructure resources efficiently, so that teams can solve business problems using a microservices approach.
Service Fabric provides two broad areas to help you build applications with a microservices approach:
- A platform consisting of a set of system services that take care of deployments, upgrades, detecting and restarting failed services, discovery of where services currently are running, state management, health monitoring, etc. These system services in effect enable many of the characteristics of microservices described above.
- Programming APIs, or frameworks, to help you build applications as microservices. The supplied programming APIs are called reliable actors and reliable services. Of course, you can use any code of your choice to build your microservice. But these APIs make the job more straightforward, and they integrate with the platform at a deeper level. This way, for example, you can get health and diagnostics information or you can take advantage of built-in high availability.
Service Fabric is agnostic on how you build your service, and you can use any technology. However, it does provide built-in programming APIs that make it very easy to build microservices.

Practice Velocity
Practice Velocity
Deck Commerce
Jeff Tucker
Director of Technology & Development | Deck Commerce